2025-07-29-九格通用基础大模型环境配置
post on 29 Jul 2025 about 3345words require 12min
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
九格通用基础大模型环境配置
模型介绍
启元九格大模型是由启元实验室联合清华大学、哈尔滨工业大学、中国科学院计算技术研究所、北京大学、南开大学等顶尖科研单位共同研发的高效模型。具备高效训练与推理、高效适配与部署的特点,支持多种自然语言处理(NLP)和多模态任务,包括文本问答、文本分类、机器翻译、文本摘要、图文理解等。模型有4B、7B、70B三种不同尺寸的基础语言模型,适配Nvidia GPU和昇腾NPU。环境配置方法和离线批量推理/在线多轮对话的示例代码均已开源。九格模型已经适配到910B npu,支持vllm离线推理和openai api访问。
我的环境配置
- python 3.10.16
- cuda11.8
流程
配置环境
1
2
3
4
5
conda create -n fm9g4bv python=3.10.16
conda activate fm9g4bv
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
克隆项目
这里克隆的是main分支,没有克隆-V后缀的分支,-V后缀的分支 有对应的推理和微调的代码以及requirements.txt文件 -V分支的链接
1
2
3
4
5
git clone https://osredm.com/p49102387/CPM-9G-8B.git
cd CPM-9G-8B
wget https://github.com/vllm-project/vllm/releases/download/v0.10.0/vllm-0.10.0+cu118-cp38-abi3-manylinux1_x86_64.whl
创建 requirements.txt文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
packaging==23.2
addict==2.4.0
editdistance==0.6.2
einops==0.8.0
fairscale==0.4.0
jsonlines==4.0.0
markdown2==2.4.10
matplotlib==3.7.4
more_itertools==10.1.0
nltk==3.8.1
numpy==1.24.4
opencv_python_headless==4.5.5.64
openpyxl==3.1.2
Pillow==10.1.0
sacrebleu==2.3.2
seaborn==0.13.0
shortuuid==1.0.11
spacy==3.7.2
torch==2.2.0
torchaudio==2.2.0
torchvision==0.17.0
timm==0.9.10
tqdm==4.66.1
protobuf==4.25.0
typing_extensions==4.8.0
uvicorn==0.24.0.post1
#xformers==0.0.22.post7
#flash_attn==2.3.4
sentencepiece==0.1.99
accelerate==0.30.1
socksio==1.0.0
gradio
gradio_client
<http://thunlp.oss-cn-qingdao.aliyuncs.com/multi_modal/never_delete/modelscope_studio-0.4.0.9-py3-none-any.whl>
decord
aiosignal
tensorboard
deepspeed==0.12.3
transformers==4.44.2
librosa==0.9.0
soundfile==0.12.1
vector-quantize-pytorch==1.18.5
vocos==0.1.0
peft==0.14.0
ninja==1.11.1.1
moviepy
1
2
3
pip install -r requirements.txt
pip install vllm-0.10.0+cu118-cp38-abi3-manylinux1_x86_64.whl
1
2
3
4
mkdir ckpt
cd cpkt
wget https://thunlp-model.oss-cn-wulanchabu.aliyuncs.com/FM9G4B-V.tar.gz
tar -xzf FM9G4B-V.tar.gz
放置推理文件
后面可以尝试微调的,这里只试了推理的 所有分支-启元实验室/九格通用基础大模型
1
2
cd ..
创建chat.py文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
"""
Name chat.py
Date 2025/5/6 11:20
Version 1.0
TODO:
"""
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
if __name__ == '__main__':
prompt = f"""### 背景 ###
您需要对图片中的内容进行识别。
### 输出格式 ###
您的输出由以下两部分组成,确保您的输出包含这两部分:
### 思考 ###
考虑饮料外的标识,辨别饮料的种类,饮料容器。并且识别饮料为'有糖'或者'无糖',给出你的思考过程。
### 识别结果 ###
若图中出现了饮料,请以json形式从左到右对他们进行描述,包括饮料:种类,是否有糖,饮料容器。
"""
model_file = 'ckpt/FM9G4B-V' ### 这里要改成你的bin文件对应的*目录*
model = AutoModel.from_pretrained(model_file, trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_file, trust_remote_code=True)
image = Image.open('step.jpg').convert('RGB')
msgs = [{'role': 'user', 'content': [image, prompt]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print("\n", "="*100, "\n")
print(res)
# 第二轮聊天,传递多轮对话的历史信息
msgs.append({"role": "assistant", "content": [res]})
msgs.append({"role": "user", "content": ["图中有几个箱子?"]})
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print("\n", "="*100, "\n")
print(answer)
## 流式输出,设置:
# sampling=True
# stream=True
## 返回一个生成器
msgs = [{'role': 'user', 'content': [image, prompt]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
print("\n", "="*100, "\n")
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')
加入setup.jpg文件

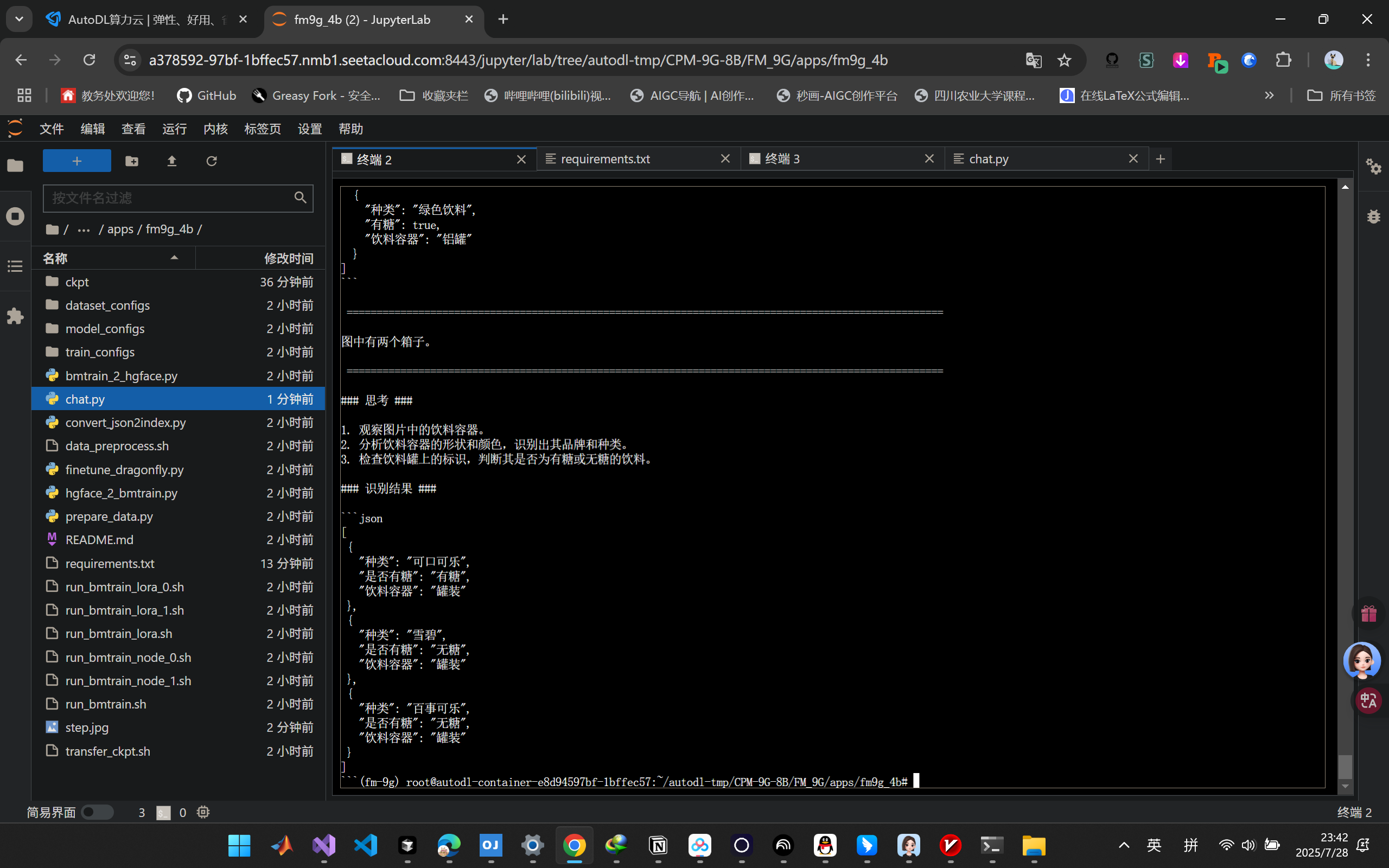
运行推理
1
python chat.py
推理结果
Related posts
Loading comments...