2025-05-11-域适应(Domain Adaptation)
post on 11 May 2025 about 3890words require 13min
CC BY 4.0 (除特别声明或转载文章外)
如果这篇博客帮助到你,可以请我喝一杯咖啡~
2025-05-11-域适应(Domain Adaptation)
相关资源
【機器學習 2021】概述領域自適應 (Domain Adaptation) 李宏毅_哔哩哔哩_bilibili
Motivation:
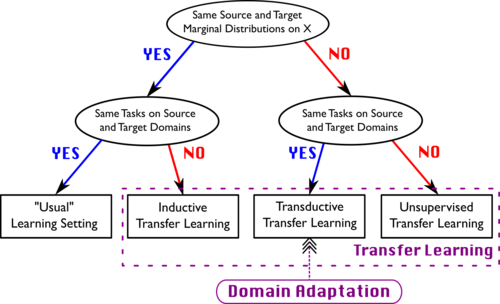
减少源领域和目标领域之间的分布差异,使得模型能够在目标领域上有效地应用,即使目标领域的数据分布与源领域有所不同。
Method:
1_Domain Adversarial Training (DAT)
DAT 通过构建一个 对抗神经网络架构 来减少源领域和目标领域之间的分布差异。这个架构通常由两个部分组成:
- 特征提取器(Feature Extractor):这个模块的任务是从输入数据中提取特征,不管这些数据来自源领域还是目标领域。它尽量学习到能够表示所有数据的特征。
- 领域判别器(Domain Classifier):这个模块的任务是区分数据来自源领域还是目标领域。模型的目标是让领域判别器无法判断出数据的来源,即源领域和目标领域的特征应该是不可区分的。
- 任务分类器(Task Classifier):这是模型的主任务部分,例如图像分类器、语音识别模型等。它负责根据输入数据做出相应的任务预测(如分类、回归等),在下面的图中就是对应的 Label predictor。
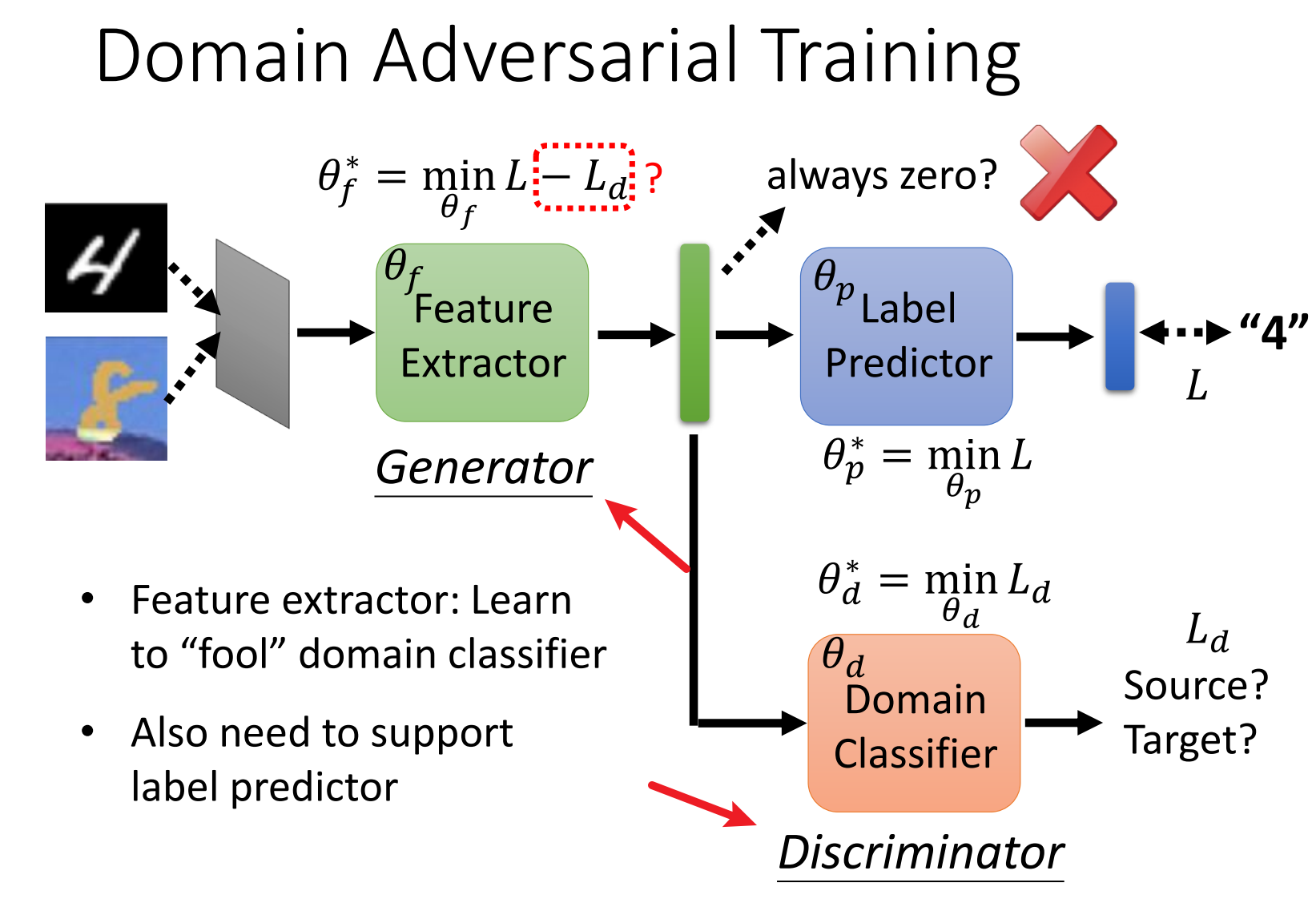
- 图中 Generator 和 Discriminator 的目标是相反的,对应的结构和 Gan 网络的结构非常的类似
- 公式 $\theta_f^*=\min {L-L_d}$中 $L_{d}$不是越小越好,因为$L_{d}$太小的话,从另外的角度 Generator 还是能够识别出 S 与 T 域之间的区别,而我们的任务是要实现 L 低的同时,Discriminator 无法识别 S 与 T 域之间的区别,但是实际训练中,对应的公式还是够用的
目标:
- 最大化任务分类器的性能:任务分类器应该能够在源领域和目标领域的共享特征上做出正确的预测。
- 最小化领域判别器的性能:领域判别器应该无法区分源领域和目标领域的数据,即模型的特征表示对于源领域和目标领域是共享的。
训练过程:
- 特征提取器和任务分类器会一起训练,目标是让任务分类器在源领域和目标领域的数据上都能有效地进行任务预测。
- 领域判别器则与特征提取器对抗训练,目的是使得特征提取器提取的特征对源领域和目标领域是不可区分的(即最大程度地消除源领域和目标领域之间的差异)。
2_Desicion Boundary(决策边界)
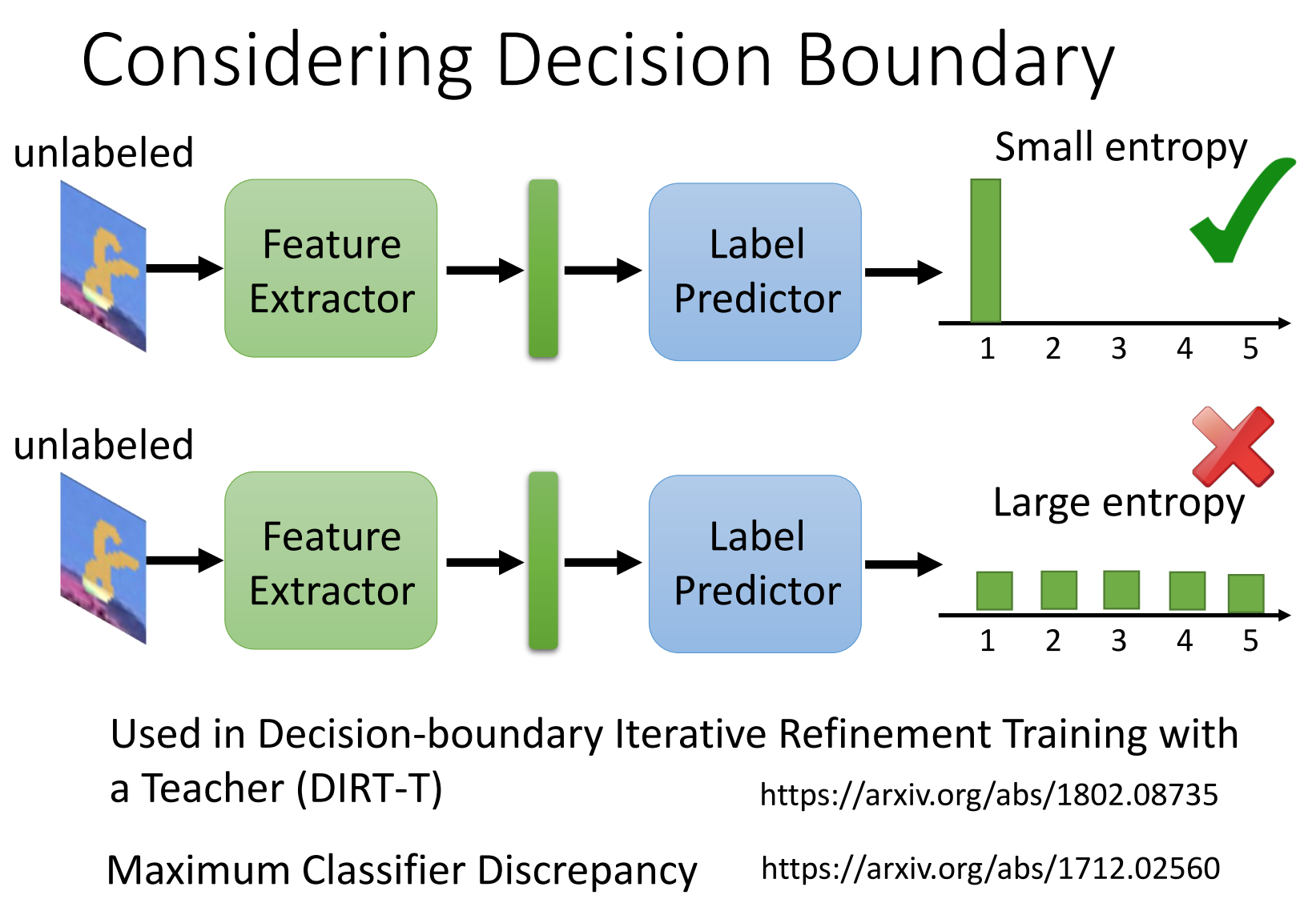
- 特征提取器(Feature Extractor):这是一个用于从输入图像中提取特征的模块。在图片中,未标记的图像输入通过特征提取器后,送入到后续的标签预测器中。
- 标签预测器(Label Predictor):这个模块负责根据从特征提取器获得的特征,预测标签。预测的标签是一个类别分布。
- 小熵(Small entropy):在上方的图示中,图像的标签预测分布显示出一个小的熵值,即该模型对预测类别有很强的信心,预测结果集中在一个类别上,显示为一个尖锐的条形图,表示标签的确定性。
- 大熵(Large entropy):在下方的图示中,标签预测分布的熵较大,表示模型对不同类别的预测没有明确偏向,结果显示为一个较平坦的分布图,表示模型对该数据的预测不确定。
这种方法在 决策边界迭代精炼训练(DIRT-T) 中使用,旨在通过对未标记数据的预测熵进行优化,使得模型在决策边界附近的预测更加精确,从而提高分类性能。
DIRT-T (Decision-boundary Iterative Refinement Training with a Teacher)
DIRT-T (Decision-boundary Iterative Refinement Training with a Teacher)
DIRT-T 是一种用于无监督学习的训练方法,特别是在半监督学习中常见。通过决策边界的迭代精炼来提升模型在无标签数据上的性能。具体来说,DIRT-T 通过使用“教师”模型来帮助改进“学生”模型的预测。
有点类似知识蒸馏
主要概念:
- 决策边界(Decision Boundary):模型在特征空间中划分不同类别的边界。DIRT-T 关注的是使得模型在决策边界附近的预测更加精确。
- 教师模型(Teacher Model):这是一个预训练或较强的模型,通常在训练过程中用于为学生模型提供指导。教师模型用来生成标签或进行软标签预测,帮助学生模型进行训练。
- 迭代精炼:模型不断调整其在决策边界附近的预测,通过教师模型的指导,使得模型在这些边界区域的表现更加精确,逐步减少决策的模糊性。
- 未标记数据的学习:DIRT-T 通过对未标记数据进行学习,在决策边界附近加强模型的推理能力,尽量减少标签预测的错误。
目的:
是通过教师模型的指导,在无标签数据的基础上不断调整模型的决策边界,使得模型在目标任务上的性能提升,尤其是在训练数据非常稀缺或没有标签时。
Maximum Classifier Discrepancy (MCD)
MCD(最大分类器不一致性) 是一种用于 领域适应(Domain Adaptation)和 半监督学习 的方法,旨在最小化源领域和目标领域之间的分布差异。其基本思想是通过最大化不同模型之间的 分类器不一致性 来改善领域迁移。
主要概念:
- 分类器不一致性:在领域适应的背景下,不同的分类器(或同一分类器在不同数据上)可能会做出不同的预测。MCD 试图通过最大化这种不一致性来发现领域间的差异并加以减少。
- 最大化不一致性:具体来说,MCD 方法通过引入多个模型(如源领域模型和目标领域模型)或不同的数据视角(源数据和目标数据)进行训练,并使用分类器之间的 不一致性(如标签预测的差异)来对模型进行优化。
- 领域适应:在迁移学习中,源领域(例如,带标签的数据)和目标领域(没有标签的数据)之间存在不同的分布。MCD 通过最大化不同分类器之间的差异,学习一个更加泛化的特征表示,减少领域间的分布差异,从而提高目标领域的性能。
目的:
MCD 的目标是使得模型在源领域和目标领域上能够学习到共同的、具有广泛适用性的特征表示,从而帮助模型更好地适应目标领域的数据,尤其是在目标领域数据少或没有标签的情况下。
Resources:
因为我们后面主要研究的领域是多目标域适应,后面表格对应的都是这方面的论文
这里提供一个 github 仓库,有除了 MTDA 的其他 DA 领域的论文资源总览 GitHub - zhaoxin94/awesome-domain-adaptation: A collection of AWESOME things about domian adaptation
| [[1810.11547] Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach](https://arxiv.org/abs/1810.11547) | [seqam-lab/MTDA-ITA: Code for Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach](https://github.com/seqam-lab/MTDA-ITA) |
| [[2211.03876] CoNMix for Source-free Single and Multi-target Domain Adaptation](https://arxiv.org/abs/2211.03876) | |
| [[2104.00808v1] Curriculum Graph Co-Teaching for Multi-Target Domain Adaptation](https://arxiv.org/abs/2104.00808v1) | |
| [[2407.13771] Training-Free Model Merging for Multi-target Domain Adaptation](https://arxiv.org/abs/2407.13771) | |
| [[2007.07077] Unsupervised Multi-Target Domain Adaptation Through Knowledge Distillation](https://arxiv.org/abs/2007.07077) | |
| [[2106.03418] Multi-Target Domain Adaptation with Collaborative Consistency Learning](https://arxiv.org/abs/2106.03418) | |
| [[2210.01578] Cooperative Self-Training for Multi-Target Adaptive Semantic Segmentation](https://arxiv.org/abs/2210.01578) | |
| [[2401.05465] D3GU: Multi-Target Active Domain Adaptation via Enhancing Domain Alignment](https://arxiv.org/abs/2401.05465) | [lzhangbj/D3GU: [WACV 2024] D3GU: Multi-target Active Domain Adaptation via Enhancing Domain Alignment](https://github.com/lzhangbj/D3GU) |
Related posts