这篇文章上次修改于 204 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
堆、栈及其应用分析
参考资料
堆 (Heap) 与 栈 (Stack) 概述
栈(Stack)
数据结构视角:一种受限的线性结构,只能在同一端(栈顶)进行插入(Push)和删除(Pop),遵循 “后进先出”(LIFO)原则。
内存视角:栈区由操作系统自动分配与回收,用于存储函数调用时的局部变量、函数参数、返回地址等信息。栈空间连续,访问和分配速度极快,但容量有限(通常几 MB),每个线程都有独立栈空间。
堆(Heap)
- 数据结构视角:一种近似完全二叉树的优先队列结构(最大堆或最小堆),常用于按优先级提取元素。
- 内存视角:堆区用于动态分配内存,程序运行时可调用
new/malloc(C++)或由运行时自动分配(Python)来获取;释放时需delete/free或由垃圾回收负责。堆空间大但分配、释放开销较大,可能产生内存碎片。
数据结构视角
栈:一种线性受限结构,只允许在栈顶进行插入(Push)和删除(Pop),遵循“后进先出”(LIFO)原则。常用操作包括 push(进栈)、pop(出栈)、top(取栈顶)等,这些操作时间复杂度通常为 O(1)。栈可用数组(顺序栈)或链表(链式栈)实现,适用于函数调用、递归计算、撤销操作等场景。
使用数组模拟栈
int st[N];
// 这里使用 st[0] (即 *st) 代表栈中元素数量,同时也是栈顶下标
// 压栈 :
st[++*st] = var1;
// 取栈顶 :
int u = st[*st];
// 弹栈 :注意越界问题, *st == 0 时不能继续弹出
if (*st) --*st;
// 清空栈
*st = 0;C++ STL 中的栈
C++ 中的 STL 也提供了一个容器 std::stack,使用前需要引入 stack 头文件。
STL 中的 stack 容器提供了一众成员函数以供调用,其中较为常用的有:
元素访问
st.top()返回栈顶
修改
st.push()插入传入的参数到栈顶st.pop()弹出栈顶
容量
st.empty()返回是否为空st.size()返回元素数量
此外,std::stack 还提供了一些运算符。较为常用的是使用赋值运算符 = 为 stack 赋值,示例:
// 新建两个栈 st1 和 st2
std::stack<int> st1, st2;
// 为 st1 装入 1
st1.push(1);
// 将 st1 赋值给 st2
st2 = st1;
// 输出 st2 的栈顶元素
cout << st2.top() << endl;
// 输出: 1使用 Python 中的 list 模拟栈
st = [5, 1, 4]
# 使用 append() 向栈顶添加元素
st.append(2)
st.append(3)
# >>> st
# [5, 1, 4, 2, 3]
# 使用 pop 取出栈顶元素
st.pop()
# >>> st
# [5, 1, 4, 2]
# 使用 clear 清空栈
st.clear()堆(优先队列): 一种树形结构,即满足堆序性的完全二叉树。每个节点的值都不大于(或不小于)其父节点的值,根节点是最大值(大顶堆)或最小值(小顶堆)。常见操作包括:上浮(shift_up)、下沉(shift_down)、插入(push)和弹出(pop)堆顶元素,以及查询堆顶(top)。堆常用作优先队列,在任务调度、Dijkstra 最短路径、Top-K 计算等场景中非常常见。
堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值。
每个节点的键值都大于等于其父亲键值的堆叫做小根堆,否则叫做大根堆。STL 中的 priority_queue 其实就是一个大根堆。
(小根)堆主要支持的操作有:插入一个数、查询最小值、删除最小值、合并两个堆、减小一个元素的值。
一些功能强大的堆(可并堆)还能(高效地)支持 merge 等操作。
一些功能更强大的堆还支持可持久化,也就是对任意历史版本进行查询或者操作,产生新的版本。
C++ 堆/优先队列:默认大顶堆(priority_queue):
std::priority_queue<int> pq;
pq.push(5);
pq.push(3);
int top = pq.top(); // 5 (最大值)
pq.pop();Python 堆(heapq 最小堆):
import heapq
heap = []
heapq.heappush(heap, 3)
heapq.heappush(heap, 5)
top = heapq.heappop(heap) # 3 (最小值)- 如果需要大顶堆,可插入负值或使用第三方实现。
堆排序
堆排序是一种高效的、基于比较的排序算法。它利用了堆这种数据结构的特性。基本思想是:
**建堆 (Heapify)**:将待排序的序列构建成一个大顶堆(或小顶堆)。此时,堆顶元素就是整个序列的最大值(或最小值)。
**排序 (Sort)**:
- 将堆顶元素与序列末尾的元素交换。
- 此时,序列末尾的元素即为最大(或最小)值,已经处于正确排序位置。
- 将剩余的 n-1 个元素重新调整为一个堆。
- 重复此过程,直到所有元素都排序完毕。
堆排序的平均时间复杂度和最坏时间复杂度都是 O(nlogn)。
C++ 实现堆排序
在 C++ 中,可以利用标准库 <algorithm> 中提供的堆操作函数来方便地实现堆排序。
std::make_heap(first, last): 将指定范围[first, last)内的元素重新排列,使其成为一个大顶堆。std::sort_heap(first, last): 将一个已经建好的堆[first, last)进行排序。它会重复地将堆顶元素(最大值)移动到序列的末尾,并重新调整剩余部分为堆。
C++
#include <iostream>
#include <vector>
#include <algorithm> // 包含 make_heap, sort_heap
void print_vector(const std::vector<int>& vec) {
for (int val : vec) {
std::cout << val << " ";
}
std::cout << std::endl;
}
int main() {
std::vector<int> v = {3, 5, 1, 8, 4, 7, 2};
std::cout << "Original vector: ";
print_vector(v);
// 1. 将 vector 转换成大顶堆
std::make_heap(v.begin(), v.end());
std::cout << "After make_heap (top is max): " << v.front() << std::endl;
// 2. 对堆进行排序 (结果为升序)
std::sort_heap(v.begin(), v.end());
std::cout << "Sorted vector: ";
print_vector(v); // 输出: 1 2 3 4 5 7 8
return 0;
}Python 实现堆排序
Python 的 heapq 模块本身不直接提供一个完整的 heapsort 函数,但我们可以很容易地利用其 heappush 和 heappop 来实现。因为 heapq 是最小堆,所以 heappop 总是弹出最小值,天然适合用于升序排序。
import heapq
def heapsort_asc(iterable):
"""
使用 heapq 实现升序排序
"""
h = []
# 将所有元素压入堆中
for value in iterable:
heapq.heappush(h, value)
# 依次弹出堆中最小的元素,构成有序列表
return [heapq.heappop(h) for _ in range(len(h))]
data = [3, 5, 1, 8, 4, 7, 2]
print(f"Original list: {data}")
sorted_data = heapsort_asc(data)
print(f"Sorted list (ascending): {sorted_data}") # 输出: [1, 2, 3, 4, 5, 7, 8]
# 原地堆排序 (In-place Heap Sort)
# 这更接近于堆排序的经典实现
def heapsort_inplace(arr):
n = len(arr)
# 1. 构建大顶堆 (从最后一个非叶子节点开始)
# 注意:heapq 是最小堆,所以这里通过对负数操作来模拟大顶堆
# 或者我们手动实现大顶堆的 sift_down
# 为了简单,我们还是用 heapq 来理解,但传统实现更高效
h = []
for x in arr:
heapq.heappush(h, x)
arr[:] = [heapq.heappop(h) for _ in range(n)]
return arr
data_inplace = [3, 5, 1, 8, 4, 7, 2]
heapsort_inplace(data_inplace)
print(f"In-place sorted list: {data_inplace}")栈和堆(优先队列)各有特点:
- 数据组织:栈是线性的、受限的结构,只能从一端操作;堆是树形结构,可快速获取最大或最小元素。
- 访问效率:栈操作简单开销小;堆插入/删除需维护堆序(O(log n))。
- 应用场景:栈适合管理临时状态(如函数调用栈、表达式求值、撤销操作);堆(优先队列)适合按优先级处理元素,如操作系统任务调度、网络请求优先级、算法中的最佳-优先搜索等。
内存分配视角
在程序运行时,内存通常分为代码区、数据区、堆区和栈区。其中:
- 栈区:由系统自动管理,随函数调用而增长,每次函数调用时分配空间给局部变量、函数参数和返回地址。函数返回时,这些空间自动回收。栈分配速度快、开销低,但空间有限(常见几 MB),且每个线程都有独立的栈空间。如果栈空间不足,会导致栈溢出错误。
- 堆区:用于动态内存分配,程序员(或运行时)在运行时使用
new/malloc等申请内存,由程序员delete/free释放(在 Python/Java 等语言由垃圾回收自动释放)。堆的可用空间远大于栈,存放动态对象。堆内存碎片化的风险更高:频繁的分配和释放可能将大块连续内存切割成许多小碎片,降低利用率。 - 静态/全局区:编译时分配,程序运行前即确定,存放全局变量、静态变量和常量,在程序整个生命周期存在。
分配方式:栈的分配和回收速度极快,操作由 CPU 指令自动完成;堆的分配开销较大,一般需要额外的内存管理算法(如自由链表或分代收集),在 C++ 中需要程序员手动释放。Python 中所有对象都分配在堆上,解释器通过引用计数和垃圾回收来管理。
访问效率:由于栈内存连续、分配固定,因此访问和分配速度更高。堆内存由多个块组成,需额外指针管理,因而略慢于栈访问。此外,栈是线程私有的(线程安全),而堆是所有线程共享的(需注意并发安全)。
- C++ 栈 vs 堆 分配:
void func() {
int a = 10; // 分配在栈上
int *p = new int(20); // 分配在堆上
// ...
delete p; // 手动释放堆内存
} // 函数返回时,a 的栈空间自动释放,若忘了 delete,则 p 指向的内存泄露- Python 对象分配:
def func():
a = 10 # 10 是整数对象,存储在堆中;a 是栈帧内的局部引用
b = [1, 2, 3] # 列表对象在堆上分配
# 变量 a, b 是存放在函数调用栈帧中的引用,当函数结束,这些引用消失- Python 不需要显示释放内存,垃圾回收自动回收无用对象。
典型应用场景
函数调用与返回
当程序调用一个函数时,当前上下文(包括当前函数的局部变量、返回地址、CPU 寄存器等)会被“压栈(push)”到栈上;函数执行完成后,栈顶信息被“弹栈(pop)”,程序自动返回调用点并恢复先前状态。这种机制正是栈的典型应用。
C++ 示例
#include <iostream>
// 一个示例函数,用于演示栈帧形成
int factorial(int n) {
if (n <= 1) {
return 1;
}
// 调用 factorial(n-1) 前,会把当前的 n、返回地址等信息压入栈
return n * factorial(n - 1);
}
int main() {
int x = 5;
std::cout << "factorial(" << x << ") = " << factorial(x) << std::endl;
return 0;
}- 每次调用
factorial时,当前函数的局部变量(如n)和返回地址会压入栈;函数结束时,栈帧被弹出,返回到上一级调用点。
Python 示例
def factorial(n):
if n <= 1:
return 1
# 递归调用时,Python 会将当前函数帧压入调用栈
return n * factorial(n - 1)
if
name
== "
__main__
":
x = 5
print(f"factorial({x}) =", factorial(x))- Python 解释器内部也维护一个“调用栈”,每个函数调用都会在栈中创建一个帧(Frame),存放局部变量和执行状态。
内存管理(局部变量与函数参数)
说明
- 栈分配:编译器在编译期或运行期自动为每个函数分配固定的栈空间,用于存储局部变量和函数参数。函数结束时,这些空间会自动释放,无需程序员手动管理。
- 堆分配:程序员可在运行时动态向操作系统请求内存,使用
new/malloc(C++)或创建对象(Python)。这些内存由程序员负责释放(或由垃圾回收器回收)。
C++ 示例:栈 vs 堆
#include <iostream>
void stackExample() {
int a = 10; // 分配在栈上
int b[100]; // 数组也分配在栈上
std::cout << "a = " << a << std::endl;
std::cout << "b[0] = " << b[0] << std::endl;
} // 函数结束时,a 和 b 的栈空间自动释放
void heapExample() {
int *p = new int(20); // 在堆上分配一个 int
int *arr = new int[100];// 在堆上分配一个大小为 100 的数组
std::cout << "*p = " << *p << std::endl;
std::cout << "arr[0] = " << arr[0] << std::endl;
delete p; // 释放堆内存
delete[] arr; // 释放数组
}
int main() {
stackExample();
heapExample();
return 0;
}stackExample:变量a和数组b分配在栈上,由系统自动分配与回收。heapExample:使用new在堆上分配内存,需要手动调用delete/delete[]来释放,否则会发生内存泄漏。
Python 示例:对象分配在堆上
def memory_example():
a = 10 # 整数对象 10 存储在堆上,a 是栈帧中的一个引用
lst = [1, 2, 3] # 列表对象存储在堆上,lst 引用保存在栈帧
print(a, lst)
if
name
== "
__main__
":
memory_example()
# Python 通过引用计数和垃圾回收自动释放不再使用的对象- 在 Python 中,所有对象都分配在堆上,局部变量仅是对这些对象的引用,保存在栈帧中。函数退出时,局部引用消失,引用计数可能降为 0,垃圾回收器会回收对象。
表达式求值(逆波兰表达式)
说明
逆波兰表达式(后缀表达式)无需括号即可明确运算顺序,评估过程中需要一个栈来保存操作数、临时结果。
- 遇到操作数时,压栈
- 遇到运算符时,从栈中弹出相应数量的操作数进行计算,并将结果压回栈
- 最后栈顶即为运算结果
C++ 示例(仅支持 + - * / 四则运算)
#include <iostream>
#include <stack>
#include <sstream>
#include <string>
#include <vector>
// 将字符串拆分为逆波兰表达式的 tokens
std::vector<std::string> tokenize(const std::string &expr) {
std::vector<std::string> tokens;
std::istringstream iss(expr);
std::string token;
while (iss >> token) {
tokens.push_back(token);
}
return tokens;
}
int evalRPN(const std::vector<std::string> &tokens) {
std::stack<int> st;
for (const auto &tk : tokens) {
if (tk == "+" || tk == "-" || tk == "
_" || tk == "/") {
int b = st.top(); st.pop();
int a = st.top(); st.pop();
int res = 0;
if (tk == "+") res = a + b;
else if (tk == "-") res = a - b;
_* else if (tk == "*
") res = a * b;
else if (tk == "/") res = a / b;
st.push(res);
} else {
st.push(std::stoi(tk));
}
}
return st.top();
}
int main() {
std::string expr = "3 4 + 2 * 7 /";
// 对应中缀: ((3 + 4) * 2) / 7 = 2
auto tokens = tokenize(expr);
std::cout << "Result: " << evalRPN(tokens) << std::endl;
return 0;
}- 将逆波兰表达式拆为 token 数组,遍历时用
std::stack<int>存放操作数。每遇运算符,弹出两个操作数,计算后将结果压回栈。
Python 示例
def eval_rpn(tokens):
stack = []
for tk in tokens:
if tk in {"+", "-", "
_", "/"}:
b = stack.pop()
a = stack.pop()
if tk == "+":
stack.append(a + b)
elif tk == "-":
stack.append(a - b)
_* elif tk == "*
":
stack.append(a * b)
else:
# 对于除法,需要注意 Python 的整除与 C++ 不同
stack.append(int(a / b)) # 向零取整
else:
stack.append(int(tk))
return stack.pop()
if
name
== "
__main__
":
expr = "3 4 + 2 * 7 /".split()
print("Result:", eval_rpn(expr)) # 2- Python 用列表
stack模拟栈,操作与 C++ 版本一致。
撤销(Undo)操作
许多应用需要实现“撤销”功能,此时可将用户操作或状态快照依次压入栈,用户点击“撤销”时,再次从栈顶弹出即可恢复到上一次状态。
Python 示例:文本编辑器简易撤销栈
class TextEditor:
def
__init__
(self):
self.text = ""
self.undo_stack = [] # 存放历史状态
def write(self, s):
# 在写新内容前,将当前状态压栈
self.undo_stack.append(self.text)
self.text += s
def undo(self):
if self.undo_stack:
self.text = self.undo_stack.pop()
else:
print("Nothing to undo")
def show(self):
print(f"Current Text: '{self.text}'")
if
name
== "
__main__
":
editor = TextEditor()
editor.write("Hello")
editor.show() # Hello
editor.write(", World!")
editor.show() # Hello, World!
editor.undo()
editor.show() # Hello
editor.undo()
editor.show() # (空字符串)- 每次写入之前,将
self.text的旧值压入undo_stack。调用undo()时,将栈顶字符串弹出并恢复。
浏览器后退功能
浏览器维护一个“历史页面访问栈”:
- 用户访问新页面时,将当前页面地址压入“后退栈”,同时清空“前进栈”
- 点击“后退”时,将当前页面压入“前进栈”,并从“后退栈”弹出最近访问的页面
- 点击“前进”时,则反向操作
Python 示例:简易浏览器历史
class BrowserHistory:
def __init__(self, homepage: str):
self.back_stack = [] # 后退栈
self.forward_stack = [] # 前进栈
self.current = homepage # 当前页面
def visit(self, url: str):
self.back_stack.append(self.current)
self.current = url
self.forward_stack.clear() # 新访问清空前进历史
def back(self):
if self.back_stack:
self.forward_stack.append(self.current)
self.current = self.back_stack.pop()
else:
print("No pages to go back to")
def forward(self):
if self.forward_stack:
self.back_stack.append(self.current)
self.current = self.forward_stack.pop()
else:
print("No pages to go forward to")
def show(self):
print(f"Back: {self.back_stack}, Current: {self.current}, Forward: {self.forward_stack}")
if name == "__main__":
browser = BrowserHistory("homepage.com")
browser.show()
browser.visit("news.com")
browser.show()
browser.visit("sports.com")
browser.show()
browser.back()
browser.show()
browser.back()
browser.show()
browser.forward()
browser.show()- 通过两个栈 (
back_stack和forward_stack) 维护历史访问记录,实现后退和前进功能。
语法分析与括号匹配
在编译器或解释器的语法分析阶段,需要检查表达式或语句是否合法。最常见的是括号匹配问题:扫描字符串时,遇到左括号((、[、{)时压栈,遇到右括号时检查栈顶是否是对应的左括号,若不匹配则报错;最后栈为空则匹配成功。
C++ 示例:括号匹配
#include <iostream>
#include <stack>
#include <string>
#include <unordered_map>
bool isValid(const std::string &s) {
std::stack<char> st;
std::unordered_map<char, char> pairs = {
{')', '('}, {']', '['}, {'}', '{'}
};
for (char c : s) {
if (c == '(' || c == '[' || c == '{') {
st.push(c);
} else if (c == ')' || c == ']' || c == '}') {
if (st.empty() || st.top() != pairs[c]) {
return false;
}
st.pop();
}
// 忽略其他字符
}
return st.empty();
}
int main() {
std::string s1 = "([{}])";
std::string s2 = "([}{])";
std::cout << s1 << " is " << (isValid(s1) ? "valid\n" : "invalid\n");
std::cout << s2 << " is " << (isValid(s2) ? "valid\n" : "invalid\n");
return 0;
}- 使用
std::stack<char>存储左括号,遇到右括号时检查对应关系。
Python 示例
def is_valid(s: str) -> bool:
stack = []
pairs = {')': '(', ']': '[', '}': '{'}
for c in s:
if c in '([{':
stack.append(c)
elif c in ')]}':
if not stack or stack[-1] != pairs[c]:
return False
stack.pop()
# 忽略其他字符
return not stack
if name == "__main__":
print(is_valid("([{}])")) # True
print(is_valid("([}{])")) # False- 逻辑同上,用列表模拟栈。
进程/线程调度与上下文切换
操作系统在进行线程切换或进程切换时,需要保存当前执行状态(寄存器上下文、程序计数器等)到线程/进程的栈帧中,待下次重新调度时再从栈中恢复。
- 线程栈:每个线程分配固定大小的栈空间,保存其调用链和临时变量。上下文切换时,CPU 会自动“压栈”通用寄存器和程序计数器,然后加载下一个线程的寄存器和 PC 值;切回原线程时,再次“弹栈”恢复上下文。
C++ 伪示例(伪代码,仅用于说明概念)
struct CPUContext {
uint64_t rip; // 指令指针(程序计数器)
uint64_t rsp; // 栈指针
uint64_t regs[16];// 其他通用寄存器
// ...
};
void context_switch(CPUContext *cur, CPUContext
_next) {
// 保存当前上下文到 cur
asm volatile (
"mov %%rsp, %0\n\t"
"mov %%rax, %1\n\t"
// … 其他寄存器
_* : "=m"(cur->rsp), "=m"(cur->regs[0]) /*
…
_/
:
:
);
// 加载下一个上下文
asm volatile (
"mov %0, %%rsp\n\t"
"mov %1, %%rax\n\t"
// … 其他寄存器
:
_* : "m"(next->rsp), "m"(next->regs[0]) /*
… */
);
// 跳转到下一个线程的指令地址
asm volatile ("jmp *%0" :: "m"(next->rip));
}- 该示例仅示意 OS 如何将寄存器状态压栈/存储到
CPUContext结构,模拟上下文切换。真实内核会更复杂,并在内核栈上完成这些操作。
实时系统任务调度与中断处理
在实时系统(RTOS)中,每个任务通常分配一个固定大小的栈,用于保存用户态执行时的局部变量和调用帧。
- 任务调度:RTOS 按优先级或时间片轮转调度任务,切换时需保存/恢复任务上下文(寄存器、程序计数器等)到各自任务的栈帧。
- 中断处理:发生中断时,CPU 自动将部分寄存器(如程序计数器、标志寄存器)压入当前栈中,跳转到中断处理程序,并使用中断程序自身的栈(通常也是内核栈)执行,处理完毕后从栈中弹出恢复现场。
C 示例(伪代码,基于 ARM Cortex-M 中断栈)
// 假设 Cortex-M 架构,中断发生时硬件会自动压入 R0-R3、R12、LR、PC、xPSR
void SysTick_Handler(void) {
// 此时硬件已将通用寄存器和 xPSR 压入当前任务的栈中,使用 PSP/MSP 寄存器区分
// 处理中断逻辑
// ...
// 退出中断时,硬件自动从栈中弹回寄存器并恢复现场
}
// 任务创建时,手动构造该任务的初始栈帧
uint32_t *create_task_stack(void (*task_func)(void), uint32_t *stack_top) {
// 栈顶需预留硬件自动压栈的空间(8 寄存器)
*(--stack_top) = INITIAL_xPSR; // xPSR
*(--stack_top) = (uint32_t)task_func; // PC
*(--stack_top) = 0xFFFFFFFD; // LR (使用 PSP 指向任务栈)
// R12, R3, R2, R1, R0
for (int i = 0; i < 5; i++) {
*(--stack_top) = 0;
}
// 接下来是软件自动压入的寄存器(R4–R11)
for (int i = 0; i < 8; i++) {
*(--stack_top) = 0;
}
return stack_top; // 返回任务上下文初始化后的栈顶指针
}- 在 ARM Cortex-M 系列中,中断或异常发生时,硬件会自动将 R0–R3、R12、LR、PC、xPSR 压栈;退出时硬件弹栈恢复。这段伪代码展示了如何手动为一个新任务构造“假”的中断栈帧,使其从任务函数
task_func开始执行。
堆与栈在内存中的分布及冲突
内存布局示意
C 语言的内存模型分为 5 个区:栈区、堆区、静态区、常量区、代码区。每个区存储的内容如下:
- 栈区:存放函数的参数值、局部变量等,由编译器自动分配和释放,通常在函数执行完后就释放了,其操作方式类似于数据结构中的栈。栈内存分配运算内置于 CPU 的指令集,效率很高,但是分配的内存量有限,比如 iOS 中栈区的大小是 2M。
- 堆区:就是通过 new、malloc、realloc 分配的内存块,编译器不会负责它们的释放工作,需要用程序区释放。分配方式类似于数据结构中的链表。“内存泄漏”通常说的就是堆区。
- 静态区:全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。
- 常量区:常量存储在这里,不允许修改。
- 代码区:顾名思义,存放代码。
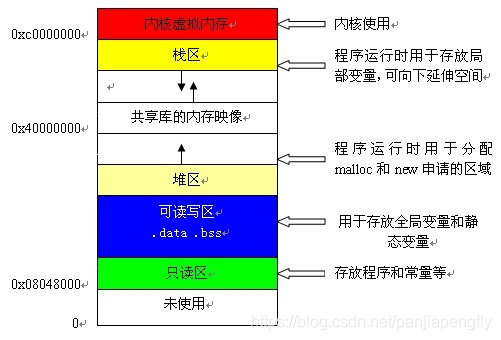
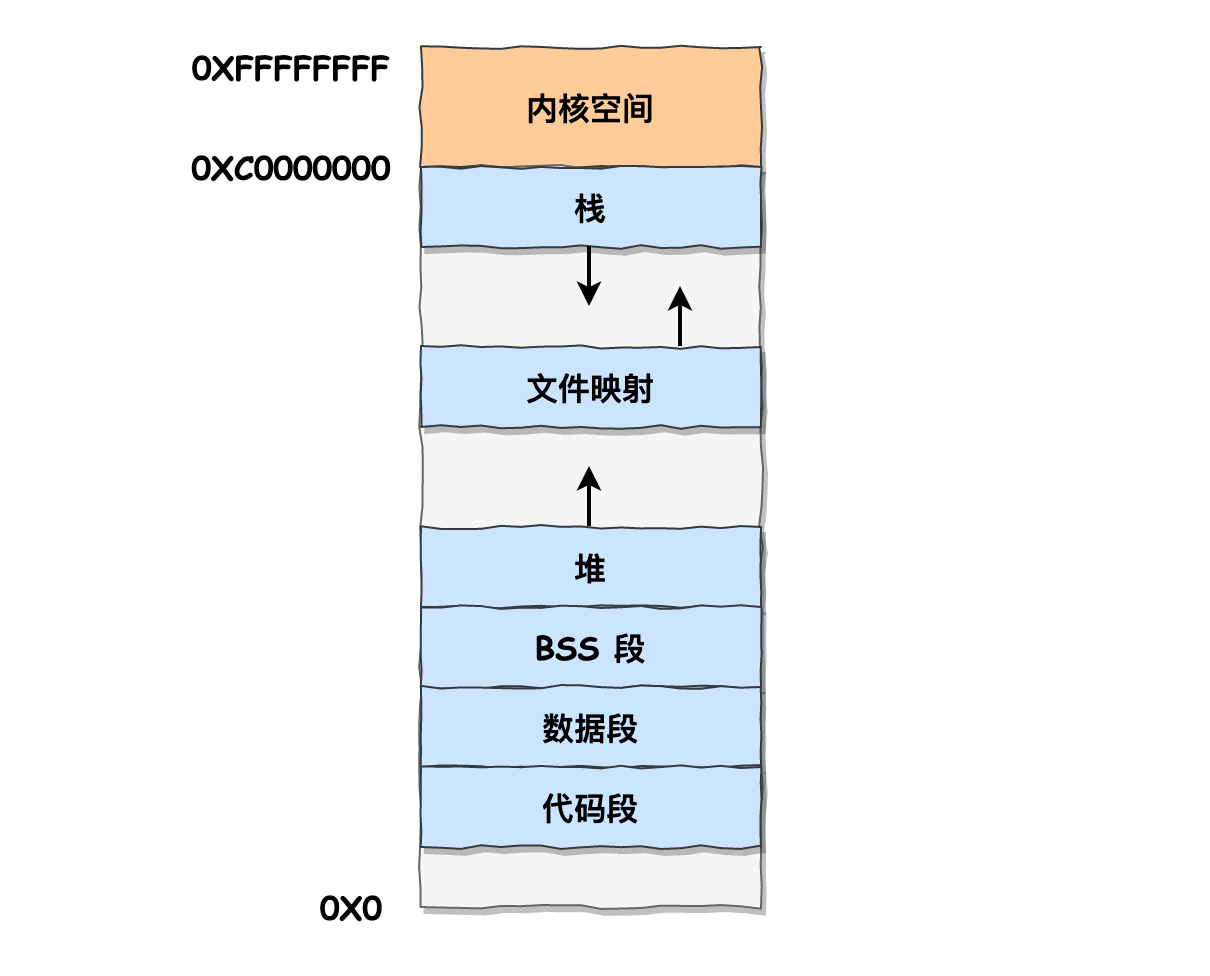
- 堆区(Heap)从低地址向高地址方向增长。当程序调用
new/malloc分配内存时,分配器会在堆中寻找足够大的空闲块。 - 栈区(Stack)从高地址向低地址方向增长。当函数调用时,系统在栈顶“向下”分配栈帧;函数返回时,“向上”回收。
- 两者通常由中间的空闲区隔开,若向对方增长的空间过大,可能出现堆与栈冲突(Stack–Heap Collision)。
栈堆冲突(Stack–Heap Collision)
当程序对堆申请大量连续内存(如 new/malloc)而栈调用层次过深(或线程栈空间不足)时:
- 堆过度增长:不断调用动态分配函数,导致堆区不断向高地址扩展
- 栈过度生长:深度递归或大量局部变量导致栈区向低地址扩展
若二者相向增长,最终会相互覆盖(即“冲突”),造成已分配的堆内存或栈空间被意外覆盖,导致程序崩溃或不可预知的错误。
示意场景
#include <iostream>
#include <vector>
void recurse(int depth) {
// 每次调用消耗一定的栈空间
char buffer[1024]; // 1KB 的局部数组
if (depth > 0) {
recurse(depth - 1);
}
}
int main() {
// 不断分配堆内存
std::vector<int*> allocations;
try {
while (true) {
allocations.push_back(new int[10000]); // 每次分配 ~40KB
}
} catch (std::bad_alloc &e) {
std::cerr << "Heap exhausted: " << e.what() << std::endl;
}
// 同时进行深度递归
recurse(100000); // 这会导致栈溢出
return 0;
}- 在上述伪示例中,如果同时执行大量
new int[10000](堆分配)与深度递归recurse(100000)(栈分配),就可能发生堆与栈冲突。实际运行时,程序要么先出现堆分配失败(抛出bad_alloc),要么先出现栈溢出 (Stack Overflow)。
如何避免
- 控制递归深度,或使用迭代替代深度递归,从而减少栈空间消耗。
- 限制堆分配总量,在堆分配时及时释放不再使用的内存,避免过度占用。
- 增加可用内存:在嵌入式或受限环境下,根据需求调整栈大小(编译器或链接器选项)和堆区大小。
- 监控与检测工具:使用工具(如 Valgrind、AddressSanitizer)检测内存越界和栈溢出问题。
堆与栈在不同应用场景中的现实案例
嵌入式开发
- 堆与栈在 RTOS 中的角色
- 栈:每个任务分配固定大小的任务栈,用于存储任务函数的调用帧和局部变量。RTOS 切换任务时,会保存/恢复任务的寄存器上下文到各自的任务栈中。
- 堆:嵌入式往往内存紧张,避免动态分配;如果使用堆则要小心碎片化。许多 RTOS(如 FreeRTOS)提供“内存池”或“堆区域”管理接口,开发者可根据需求预先分配一段大内存作为堆,通过
pvPortMalloc/vPortFree操作。
// FreeRTOS 示例:创建一个任务,并为其指定栈大小
void vTaskFunction(void *pvParameters) {
int local_var = 42; // 存储在任务栈中
for (;;) {
// Task logic...
}
}
int main(void) {
// 在创建任务时,指定 256 字 作为任务栈大小
xTaskCreate(vTaskFunction, "Task1", 256, NULL, 1, NULL);
vTaskStartScheduler(); // 启动调度器,开始抢占式多任务
return 0;
}- 场景说明:在嵌入式系统中,为了保证实时性和预测性,往往禁止或限制堆分配,更多地使用静态分配或内存池,仅在启动阶段少量使用堆。
Web 后端
函数调用与请求栈
- 在 Web 服务中,每个 HTTP 请求都可能触发一条线程(或使用协程/异步框架),该请求对应的调用堆栈存放在栈内存中。若请求处理链条过深(大量中间件或控制器嵌套),有可能导致栈溢出。
缓存管理
- 堆:Java 或 C++ 编写的后端应用中的缓存(如 LRU Cache)通常使用堆结构来维护元素优先级或过期时间。例如,使用
std::priority_queue或 Python 的heapq实现定时淘汰策略。
- 堆:Java 或 C++ 编写的后端应用中的缓存(如 LRU Cache)通常使用堆结构来维护元素优先级或过期时间。例如,使用
C++ 示例:基于堆的简单 LRU 缓存(按过期时间)
#include <iostream>
#include <queue>
#include <unordered_map>
#include <chrono>
#include <thread>
struct CacheItem {
int key;
std::string value;
std::chrono::steady_clock::time_point expire_time;
};
struct CompareExpire {
bool operator()(const CacheItem &a, const CacheItem &b) {
return a.expire_time > b.expire_time; // 过期时间早的优先级高
}
};
class LRUCache {
public:
LRUCache(size_t capacity): capacity_(capacity) {}
void put(int key, const std::string &value, int ttl_seconds) {
auto now = std::chrono::steady_clock::now();
CacheItem item{key, value, now + std::chrono::seconds(ttl_seconds)};
if (cache_map_.size() >= capacity_) {
// 移除过期或最久未使用元素
evict();
}
cache_map_[key] = item;
min_heap_.push(item);
}
std::string get(int key) {
auto it = cache_map_.find(key);
if (it == cache_map_.end()) return ""; // 未命中
// 更新过期时间或移动到最新位置可自行实现
return it->second.value;
}
private:
void evict() {
auto now = std::chrono::steady_clock::now();
while (!min_heap_.empty()) {
auto &top = min_heap_.top();
if (top.expire_time <= now) {
// 已过期,删除
cache_map_.erase(top.key);
min_heap_.pop();
} else {
// 如果堆顶未过期,但 cache_map_ 超过容量,可自行实现额外的 LRU 逻辑
break;
}
}
// 这里简化:如果仍然超出容量,可额外删除最老元素
}
size_t capacity_;
std::unordered_map<int, CacheItem> cache_map_;
std::priority_queue<CacheItem, std::vector<CacheItem>, CompareExpire> min_heap_;
};
int main() {
LRUCache cache(3);
cache.put(1, "A", 2);
cache.put(2, "B", 5);
cache.put(3, "C", 10);
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << "Get key 1: " << cache.get(1) << std::endl; // 可能已过期,返回 ""
return 0;
}- 使用
std::priority_queue(最小堆)按过期时间排序,当容量满时弹出最早过期项或其他淘汰策略。
游戏开发
- 内存池(Memory Pool)
- 游戏中对象(如子弹、特效、NPC)创建频繁,反复调用
new/delete会导致堆碎片和性能损耗。常用的做法是在启动时预先向堆申请一大块连续内存,将其切分为固定大小的“内存池块”,通过栈或链表管理空闲块。分配时从池中取出一个空闲块,释放时将其归还池中,而无需操作系统的堆管理。
- 游戏中对象(如子弹、特效、NPC)创建频繁,反复调用
C++ 示例:简单对象池(以 GameObject 为例)
#include <iostream>
#include <vector>
// 假设游戏对象
class GameObject {
public:
GameObject() : x(0), y(0) {}
void reset() { x = y = 0; }
void set_position(int px, int py) { x = px; y = py; }
void print() const { std::cout << "GameObject at (" << x << ", " << y << ")\n"; }
private:
int x, y;
};
class ObjectPool {
public:
ObjectPool(size_t poolSize) {
pool_.reserve(poolSize);
for (size_t i = 0; i < poolSize; ++i) {
pool_.push_back(new GameObject());
free_stack_.push(pool_.back());
}
}
~ObjectPool() {
for (auto obj : pool_) delete obj;
}
GameObject* acquire() {
if (free_stack_.empty()) return nullptr;
GameObject* obj = free_stack_.top();
free_stack_.pop();
return obj;
}
void release(GameObject* obj) {
obj->reset();
free_stack_.push(obj);
}
private:
std::vector<GameObject*> pool_;
std::stack<GameObject*> free_stack_;
};
int main() {
ObjectPool pool(5);
GameObject *obj1 = pool.acquire();
obj1->set_position(10, 20);
obj1->print(); // GameObject at (10, 20)
pool.release(obj1);
GameObject *obj2 = pool.acquire();
obj2->print(); // GameObject at (0, 0) (重置后)
return 0;
}ObjectPool在构造时一次性向堆申请若干GameObject,将它们全部存在pool_容器中,再把指针压入free_stack_(栈)。获取时从free_stack_弹栈;释放时将对象reset()并压回栈。避免了频繁的new/delete。
操作系统原理
线程栈
- 操作系统为每个线程分配固定大小的内存作为线程栈,用于保存函数调用帧、局部变量和中断上下文。栈空间不足会导致栈溢出(Stack Overflow),可能使程序崩溃。
堆碎片与分配器
- 应用在堆上频繁分配/释放不同大小的块,会导致碎片化(外部碎片)。操作系统或 C 运行时使用分配算法(如伙伴系统、空闲链表、slab 分配器)来减少碎片。例如 Linux 内核使用伙伴算法(Buddy Allocator)为内核分配物理页;用户态 C 库(glibc)使用 ptmalloc2,实现复杂的 bin 快表和 mmap 分配,从而提升多线程环境下的分配效率并尽量减少碎片。
总结
总体而言,栈与堆在数据结构和内存管理层面都是基础而关键的概念。数据结构层面,栈提供简单高效的 LIFO 存取,堆(优先队列)提供基于优先级的动态调度;内存管理层面,栈由系统自动分配释放,速度快但空间有限;堆则按需动态分配,由程序或运行时负责回收,灵活但需要注意碎片和内存泄漏。理解两者的差异及应用场景(如嵌入式的静态分配、后端的请求栈和缓存管理、游戏的内存池、操作系统的线程栈管理等)可以帮助程序员写出更健壮、高效的代码。
- 栈:自动分配与释放;访问速度快;适用于函数调用、状态机、撤销等场景;容量有限且线程私有。
- 堆:动态分配与释放;灵活但开销较大;可能发生碎片;适用于缓存管理、对象池、动态数据结构等场景。
- 理解两者在内存布局上的位置及增长方式,有助于避免栈溢出和堆栈冲突,提高程序安全性与性能。
