这篇文章上次修改于 275 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
实例分割(Instance Segmentation)
** 定义**
实例分割是目标检测和语义分割的结合,旨在精确识别图像中的每个目标对象,并区分同一类别中的不同实例。例如,在一张包含多个人的图像中,实例分割不仅需要识别出“人”这一类别,还需要将每个人单独区分开来,为每个人生成独立的分割掩码(Mask)。
实例分割通过融合目标检测和语义分割的结果来实现这一目标。具体而言,它利用目标检测提供的目标类别和位置信息(如边界框和置信度),从语义分割的结果中提取出对应目标的像素级掩码。简而言之,实例分割的任务是将同一类别中的具体对象(即实例)分别分割出来。
举个例子,近年来,随着自动驾驶等领域的快速发展,实例分割任务受到了广泛关注。自动驾驶场景中,精确区分和分割道路上的行人、车辆等目标对于环境感知和决策至关重要。此外,一些实例分割任务还会输出检测结果(如边界框),以提供更全面的目标描述。
对实例分割、语义分割和目标检测混合任务感兴趣的读者,可以参考 CVPR 2019 的论文《Hybrid Task Cascade》(HTC),该研究提出了一种混合任务级联框架,能够同时处理这三种任务,为多任务学习提供了新的思路。
特点
- 能够精确地定位和区分同一类别的不同实例。
- 计算成本较高,因为需要对每个目标实例进行单独检测和分类。
** 应用**
实例分割在以下领域有重要应用:
- 自动驾驶:用于检测和分割车辆、行人。
- 医学成像:用于检测组织和病理的特定边界。
- 机器人视觉:用于识别和隔离目标物体。
** 常见模型**
Mask R-CNN
- 优点:能够同时进行目标检测和语义分割,具有较好的性能。
- 缺点:模型参数多,训练和推理速度较慢;大目标的边缘分割较为粗糙。
提出初衷
Mask R-CNN 是 2017 年发表的文章,一作是何恺明大神,没错就是那个男人,除此之外还有 Faster R-CNN 系列的大神 Ross Girshick,可以说是强强联合。该论文也获得了 ICCV 2017 的最佳论文奖(Marr Prize)。并且该网络提出后,又霸榜了 MS COCO 的各项任务,包括目标检测、实例分割以及人体关键点检测任务。Mask R-CNN 的结构很简洁而且很灵活效果又很好(仅仅是在 Faster R-CNN 的基础上根据需求加入一些新的分支)。
Mask R-CNN 的提出初衷是为了实现高效且精确的实例分割任务,同时继承 Faster R-CNN 在目标检测方面的优势。具体而言,Mask R-CNN 的核心动机是将目标检测与语义分割相结合,既能检测图像中的目标并定位其边界框,又能为每个目标生成精确的像素级分割掩码。此外,Mask R-CNN 通过引入 RoI Align 技术,解决了 Faster R-CNN 中 RoI Pooling 导致的特征图与原始图像区域对齐不精确的问题,显著提高了分割掩码的精度。Mask R-CNN 在 Faster R-CNN 的基础上增加了全卷积网络(FCN)分支,用于预测每个感兴趣区域(RoI)的分割掩码,这种设计不仅简单高效,且只增加了较小的计算开销。
它还具备良好的多任务扩展性,能够轻松扩展到其他任务(如人体关键点检测),成为一种通用的视觉框架。通过为每个类别预测独立的二元掩码,Mask R-CNN 能够更好地提取目标的空间布局信息,从而生成更精确的分割掩码,并在 COCO 等数据集上取得了显著优于当时其他模型的性能。总之,Mask R-CNN 的提出填补了目标检测和语义分割之间的空白,提供了一种高精度、高效率的实例分割解决方案。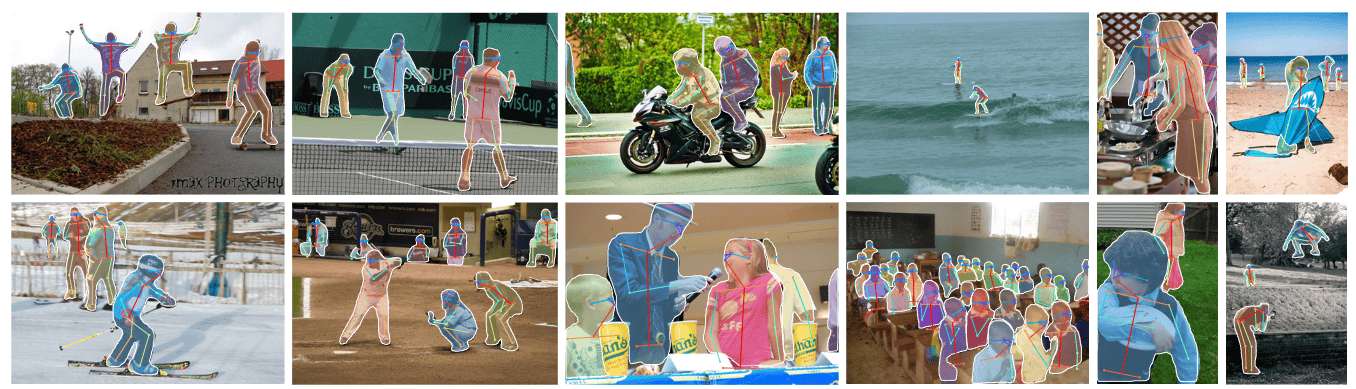
Mask R-CNN 的提出初衷是为了实现高效且精确的实例分割任务,同时继承 Faster R-CNN 在目标检测方面的优势。具体动机和背景如下:
- 结合目标检测与语义分割
在 Mask R-CNN 提出之前,目标检测(如 Faster R-CNN)和语义分割(如 FCN)是两个独立的领域。Mask R-CNN 的核心动机是将两者结合起来,既能够检测图像中的目标并定位其边界框,还能为每个目标生成精确的像素级分割掩码。 - 解决像素级对齐问题
Faster R-CNN 在处理像素级任务时存在局限性,尤其是其 RoI Pooling 操作会导致特征图与原始图像区域的对齐不精确。Mask R-CNN 通过引入 RoI Align 技术,解决了这一问题,显著提高了分割掩码的精度。 - 简单高效的架构设计
Mask R-CNN 在 Faster R-CNN 的基础上,增加了一个全卷积网络(FCN)分支,用于预测每个感兴趣区域(RoI)的分割掩码。这种设计不仅简单高效,而且只增加了较小的计算开销。 - 多任务学习的扩展性
Mask R-CNN 不仅适用于实例分割,还可以轻松扩展到其他任务,如人体关键点检测。这种多任务扩展性使其成为一种通用的视觉框架。 - 提升实例分割精度
通过为每个类别预测独立的二元掩码,Mask R-CNN 能够更好地提取目标的空间布局信息,从而生成更精确的分割掩码。这一改进使其在 COCO 等数据集上取得了显著优于当时其他模型的性能。
网络结构
Mask R-CNN 的结构也很简单,就是在通过 RoIAlign(在原 Faster R-CNN 中是 RoIPool)得到的 RoI 基础上并行添加一个 Mask 分支(小型的 FCN)。见下图,之前 Faster R-CNN 是在 RoI 基础上接上一个 Fast R-CNN 检测头,即图中 class, box 分支,现在又并行了一个 Mask 分支。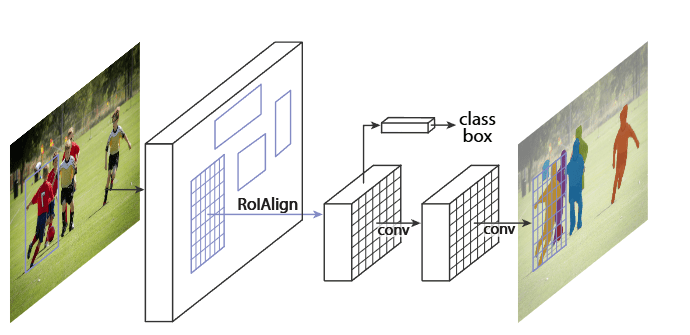
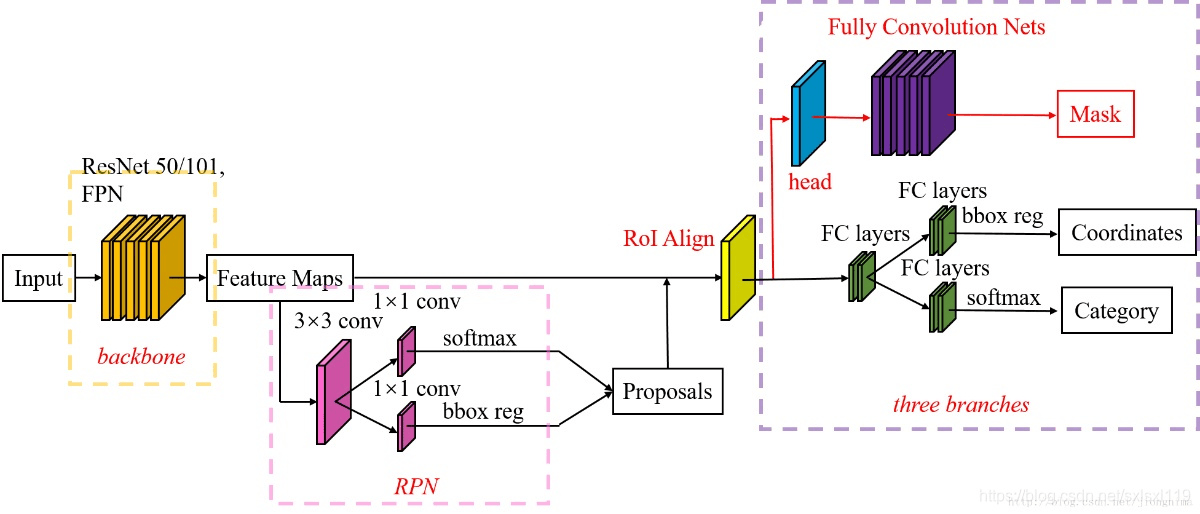
注意带和不带 FPN 结构的 Mask R-CNN 在 Mask 分支上略有不同,对于带有 FPN 结构的 Mask R-CNN 它的 class、box 分支和 Mask 分支并不是共用一个 RoIAlign。在训练过程中,对于 class, box 分支 RoIAlign 将 RPN(Region Proposal Network)得到的 Proposals 池化到 7x7 大小,而对于 Mask 分支 RoIAlign 将 Proposals 池化到 14x14 大小。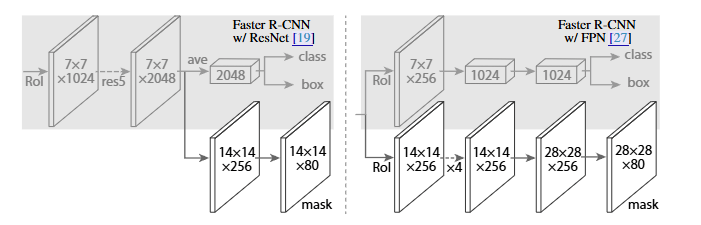
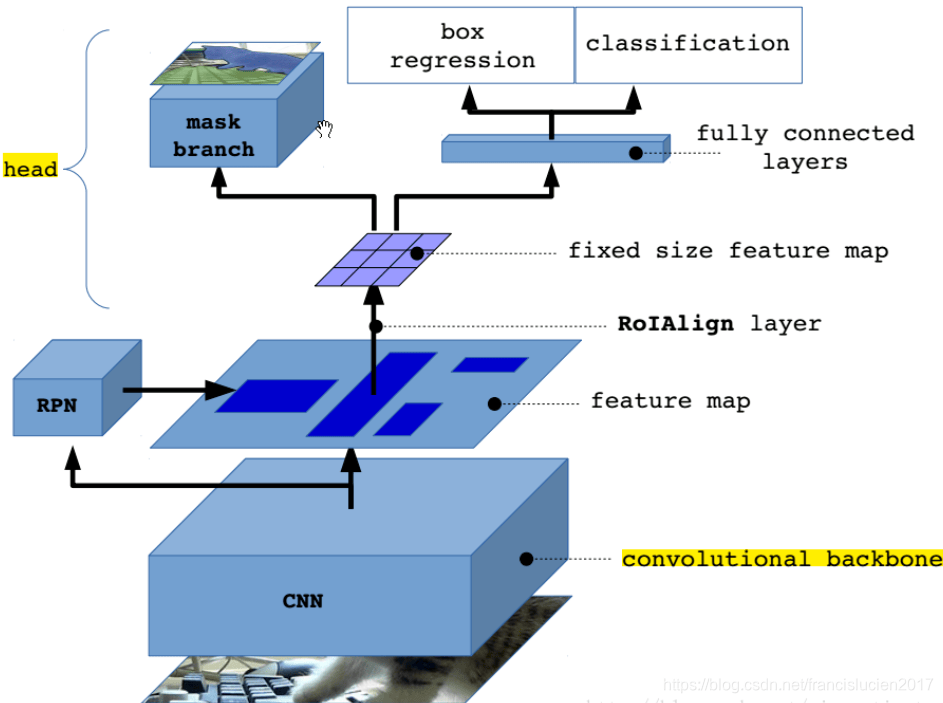
Q:Mask R-CNN 中的 RoI Align 技术是如何解决 Faster R-CNN 中 RoI Pooling 导致的特征图与原始图像区域对齐不精确的问题的呢?
模型代码
"""
Model definitions
"""
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
import numpy as np
import math
from model.resnet import resnet50
from model.rpn import RPN
#from model.lib.roi_align.roi_align.roi_align import RoIAlign
from model.lib.roi_align.roi_align.crop_and_resize import CropAndResize
from model.lib.bbox.generate_anchors import generate_pyramid_anchors
from model.lib.bbox.nms import torch_nms as nms
def log2_graph(x):
"""Implementatin of Log2. pytorch doesn't have a native implemenation."""
return torch.div(torch.log(x), math.log(2.))
def ROIAlign(feature_maps, rois, config, pool_size, mode='bilinear'):
"""Implements ROI Align on the features.
Params:
- pool_shape: [height, width] of the output pooled regions. Usually [7, 7]
- image_shape: [height, width, chanells]. Shape of input image in pixels
Inputs:
- boxes: [batch, num_boxes, (x1, y1, x2, y2)] in normalized
coordinates. Possibly padded with zeros if not enough
boxes to fill the array.
- Feature maps: List of feature maps from different levels of the pyramid.
Each is [batch, channels, height, width]
Output:
Pooled regions in the shape: [batch, num_boxes, height, width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
"""
[ x2-x1 x1 + x2 - W + 1 ]
[ ----- 0 --------------- ]
[ W - 1 W - 1 ]
[ ]
[ y2-y1 y1 + y2 - H + 1 ]
[ 0 ----- --------------- ]
[ H - 1 H - 1 ]
"""
#feature_maps= [P2, P3, P4, P5]
rois = rois.detach()
crop_resize = CropAndResize(pool_size, pool_size, 0)
roi_number = rois.size()[1]
pooled = rois.data.new(
config.IMAGES_PER_GPU*rois.size(
1), 256, pool_size, pool_size).zero_()
rois = rois.view(
config.IMAGES_PER_GPU*rois.size(1),
4)
# Loop through levels and apply ROI pooling to each. P2 to P5.
x_1 = rois[:, 0]
y_1 = rois[:, 1]
x_2 = rois[:, 2]
y_2 = rois[:, 3]
roi_level = log2_graph(
torch.div(torch.sqrt((y_2 - y_1) * (x_2 - x_1)), 224.0))
roi_level = torch.clamp(torch.clamp(
torch.add(torch.round(roi_level), 4), min=2), max=5)
# P2 is 256x256, P3 is 128x128, P4 is 64x64, P5 is 32x32
# P2 is 4, P3 is 8, P4 is 16, P5 is 32
for i, level in enumerate(range(2, 6)):
scaling_ratio = 2**level
height = float(config.IMAGE_MAX_DIM)/ scaling_ratio
width = float(config.IMAGE_MAX_DIM) / scaling_ratio
ixx = torch.eq(roi_level, level)
box_indices = ixx.view(-1).int() * 0
ix = torch.unsqueeze(ixx, 1)
level_boxes = torch.masked_select(rois, ix)
if level_boxes.size()[0] == 0:
continue
level_boxes = level_boxes.view(-1, 4)
crops = crop_resize(feature_maps[i], torch.div(
level_boxes, float(config.IMAGE_MAX_DIM)
)[:, [1, 0, 3, 2]], box_indices)
indices_pooled = ixx.nonzero()[:, 0]
pooled[indices_pooled.data, :, :, :] = crops.data
pooled = pooled.view(config.IMAGES_PER_GPU, roi_number,
256, pool_size, pool_size)
pooled = Variable(pooled).cuda()
return pooled
# ---------------------------------------------------------------
# Heads
class MaskHead(nn.Module):
def __init__(self, config):
super(MaskHead, self).__init__()
self.config = config
self.num_classes = config.NUM_CLASSES
#self.crop_size = config.mask_crop_size
#self.roi_align = RoIAlign(self.crop_size, self.crop_size)
self.conv1 = nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=1)
self.bn1 = nn.BatchNorm2d(256)
self.conv2 = nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=1)
self.bn2 = nn.BatchNorm2d(256)
self.conv3 = nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=1)
self.bn3 = nn.BatchNorm2d(256)
self.conv4 = nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=1)
self.bn4 = nn.BatchNorm2d(256)
self.deconv = nn.ConvTranspose2d(256, 256, kernel_size=4, padding=1, stride=2, bias=False)
self.mask = nn.Conv2d(256, self.num_classes, kernel_size=1, padding=0, stride=1)
def forward(self, x, rpn_rois):
#x = self.roi_align(x, rpn_rois)
x = ROIAlign(x, rpn_rois, self.config, self.config.MASK_POOL_SIZE)
roi_number = x.size()[1]
# merge batch and roi number together
x = x.view(self.config.IMAGES_PER_GPU * roi_number,
256, self.config.MASK_POOL_SIZE,
self.config.MASK_POOL_SIZE)
x = F.relu(self.bn1(self.conv1(x)), inplace=True)
x = F.relu(self.bn2(self.conv2(x)), inplace=True)
x = F.relu(self.bn3(self.conv3(x)), inplace=True)
x = F.relu(self.bn4(self.conv4(x)), inplace=True)
x = self.deconv(x)
rcnn_mask_logits = self.mask(x)
rcnn_mask_logits = rcnn_mask_logits.view(self.config.IMAGES_PER_GPU,
roi_number,
self.config.NUM_CLASSES,
self.config.MASK_POOL_SIZE * 2,
self.config.MASK_POOL_SIZE * 2)
return rcnn_mask_logits
class RCNNHead(nn.Module):
def __init__(self, config):
super(RCNNHead, self).__init__()
self.config = config
self.num_classes = config.NUM_CLASSES
#self.crop_size = config.rcnn_crop_size
#self.roi_align = RoIAlign(self.crop_size, self.crop_size)
self.fc1 = nn.Linear(1024, 1024)
self.fc2 = nn.Linear(1024, 1024)
self.class_logits = nn.Linear(1024, self.num_classes)
self.bbox = nn.Linear(1024, self.num_classes * 4)
self.conv1 = nn.Conv2d(256, 1024, kernel_size=self.config.POOL_SIZE, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(1024, eps=0.001)
def forward(self, x, rpn_rois):
x = ROIAlign(x, rpn_rois, self.config, self.config.POOL_SIZE)
roi_number = x.size()[1]
x = x.view(self.config.IMAGES_PER_GPU * roi_number,
256, self.config.POOL_SIZE,
self.config.POOL_SIZE)
#print(x.shape)
#x = self.roi_align(x, rpn_rois, self.config, self.config.POOL_SIZE)
#x = crops.view(crops.size(0), -1)
x = self.bn1(self.conv1(x))
x = x.permute(0, 2, 3, 1).contiguous().view(x.size(0), -1)
x = F.relu(self.fc1(x), inplace=True)
x = F.relu(self.fc2(x), inplace=True)
#x = F.dropout(x, 0.5, training=self.training)
rcnn_class_logits = self.class_logits(x)
rcnn_probs = F.softmax(rcnn_class_logits, dim=-1)
rcnn_bbox = self.bbox(x)
rcnn_class_logits = rcnn_class_logits.view(self.config.IMAGES_PER_GPU,
roi_number,
rcnn_class_logits.size()[-1])
rcnn_probs = rcnn_probs.view(self.config.IMAGES_PER_GPU,
roi_number,
rcnn_probs.size()[-1])
rcnn_bbox = rcnn_bbox.view(self.config.IMAGES_PER_GPU,
roi_number,
self.config.NUM_CLASSES,
4)
return rcnn_class_logits, rcnn_probs, rcnn_bbox
#
# ---------------------------------------------------------------
# Mask R-CNN
class MaskRCNN(nn.Module):
"""
Mask R-CNN model
"""
def __init__(self, config):
super(MaskRCNN, self).__init__()
self.config = config
self.__mode = 'train'
feature_channels = 128
# define modules (set of layers)
# self.feature_net = FeatureNet(cfg, 3, feature_channels)
self.feature_net = resnet50().cuda()
#self.rpn_head = RpnMultiHead(cfg,feature_channels)
self.rpn = RPN(256, len(self.config.RPN_ANCHOR_RATIOS),
self.config.RPN_ANCHOR_STRIDE)
#self.rcnn_crop = CropRoi(cfg, cfg.rcnn_crop_size)
self.rcnn_head = RCNNHead(config)
#self.mask_crop = CropRoi(cfg, cfg.mask_crop_size)
self.mask_head = MaskHead(config)
self.anchors = generate_pyramid_anchors(self.config.RPN_ANCHOR_SCALES,
self.config.RPN_ANCHOR_RATIOS,
self.config.BACKBONE_SHAPES,
self.config.BACKBONE_STRIDES,
self.config.RPN_ANCHOR_STRIDE)
self.anchors = self.anchors.astype(np.float32)
self.proposal_count = self.config.POST_NMS_ROIS_TRAINING
# FPN
self.fpn_c5p5 = nn.Conv2d(
512 * 4, 256, kernel_size=1, stride=1, padding=0)
self.fpn_c4p4 = nn.Conv2d(
256 * 4, 256, kernel_size=1, stride=1, padding=0)
self.fpn_c3p3 = nn.Conv2d(
128 * 4, 256, kernel_size=1, stride=1, padding=0)
self.fpn_c2p2 = nn.Conv2d(
64 * 4, 256, kernel_size=1, stride=1, padding=0)
self.fpn_p2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.fpn_p3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.fpn_p4 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.fpn_p5 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.scale_ratios = [4, 8, 16, 32]
self.fpn_p6 = nn.MaxPool2d(
kernel_size=1, stride=2, padding=0, ceil_mode=False)
def forward(self, x):
# Extract features
C1, C2, C3, C4, C5 = self.feature_net(x)
P5 = self.fpn_c5p5(C5)
P4 = self.fpn_c4p4(C4) + F.upsample(P5,
scale_factor=2, mode='bilinear')
P3 = self.fpn_c3p3(C3) + F.upsample(P4,
scale_factor=2, mode='bilinear')
P2 = self.fpn_c2p2(C2) + F.upsample(P3,
scale_factor=2, mode='bilinear')
# Attach 3x3 conv to all P layers to get the final feature maps.
# P2 is 256, P3 is 128, P4 is 64, P5 is 32
P2 = self.fpn_p2(P2)
P3 = self.fpn_p3(P3)
P4 = self.fpn_p4(P4)
P5 = self.fpn_p5(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = self.fpn_p6(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
self.mrcnn_feature_maps = [P2, P3, P4, P5]
rpn_class_logits_outputs = []
rpn_class_outputs = []
rpn_bbox_outputs = []
# RPN proposals
for feature in rpn_feature_maps:
rpn_class_logits, rpn_probs, rpn_bbox = self.rpn(feature)
rpn_class_logits_outputs.append(rpn_class_logits)
rpn_class_outputs.append(rpn_probs)
rpn_bbox_outputs.append(rpn_bbox)
rpn_class_logits = torch.cat(rpn_class_logits_outputs, dim=1)
rpn_class = torch.cat(rpn_class_outputs, dim=1)
rpn_bbox = torch.cat(rpn_bbox_outputs, dim=1)
rpn_proposals = self.proposal_layer(rpn_class, rpn_bbox)
# RCNN proposals
rcnn_class_logits, rcnn_class, rcnn_bbox = self.rcnn_head(self.mrcnn_feature_maps, rpn_proposals)
rcnn_mask_logits = self.mask_head(self.mrcnn_feature_maps, rpn_proposals)
# <todo> mask nms
return [rpn_class_logits, rpn_class, rpn_bbox, rpn_proposals,
rcnn_class_logits, rcnn_class, rcnn_bbox,
rcnn_mask_logits]
def proposal_layer(self, rpn_class, rpn_bbox):
# handling proposals
scores = rpn_class[:, :, 1]
#print(scores.shape)
# Box deltas [batch, num_rois, 4]
deltas_mul = Variable(torch.from_numpy(np.reshape(
self.config.RPN_BBOX_STD_DEV, [1, 1, 4]).astype(np.float32))).cuda()
deltas = rpn_bbox * deltas_mul
pre_nms_limit = min(6000, self.anchors.shape[0])
scores, ix = torch.topk(scores, pre_nms_limit, dim=-1,
largest=True, sorted=True)
ix = torch.unsqueeze(ix, 2)
ix = torch.cat([ix, ix, ix, ix], dim=2)
deltas = torch.gather(deltas, 1, ix)
_anchors = []
for i in range(self.config.IMAGES_PER_GPU):
anchors = Variable(torch.from_numpy(
self.anchors.astype(np.float32))).cuda()
_anchors.append(anchors)
anchors = torch.stack(_anchors, 0)
pre_nms_anchors = torch.gather(anchors, 1, ix)
refined_anchors = apply_box_deltas_graph(pre_nms_anchors, deltas)
# Clip to image boundaries. [batch, N, (y1, x1, y2, x2)]
height, width = self.config.IMAGE_SHAPE[:2]
window = np.array([0, 0, height, width]).astype(np.float32)
window = Variable(torch.from_numpy(window)).cuda()
refined_anchors_clipped = clip_boxes_graph(refined_anchors, window)
refined_proposals = []
scores = scores[:,:,None]
#print(scores.data.shape)
#print(refined_anchors_clipped.data.shape)
for i in range(self.config.IMAGES_PER_GPU):
indices = nms(
torch.cat([refined_anchors_clipped.data[i], scores.data[i]], 1), 0.7)
indices = indices[:self.proposal_count]
indices = torch.stack([indices, indices, indices, indices], dim=1)
indices = Variable(indices).cuda()
proposals = torch.gather(refined_anchors_clipped[i], 0, indices)
padding = self.proposal_count - proposals.size()[0]
proposals = torch.cat(
[proposals, Variable(torch.zeros([padding, 4])).cuda()], 0)
refined_proposals.append(proposals)
rpn_rois = torch.stack(refined_proposals, 0)
return rpn_rois
def apply_box_deltas_graph(boxes, deltas):
"""Applies the given deltas to the given boxes.
boxes: [N, 4] where each row is y1, x1, y2, x2
deltas: [N, 4] where each row is [dy, dx, log(dh), log(dw)]
"""
# Convert to y, x, h, w
height = boxes[:, :, 2] - boxes[:, :, 0]
width = boxes[:, :, 3] - boxes[:, :, 1]
center_y = boxes[:, :, 0] + 0.5 * height
center_x = boxes[:, :, 1] + 0.5 * width
# Apply deltas
center_y += deltas[:, :, 0] * height
center_x += deltas[:, :, 1] * width
height *= torch.exp(deltas[:, :, 2])
width *= torch.exp(deltas[:, :, 3])
# Convert back to y1, x1, y2, x2
y1 = center_y - 0.5 * height
x1 = center_x - 0.5 * width
y2 = y1 + height
x2 = x1 + width
result = [y1, x1, y2, x2]
return result
def clip_boxes_graph(boxes, window):
"""
boxes: [N, 4] each row is y1, x1, y2, x2
window: [4] in the form y1, x1, y2, x2
"""
# Split corners
wy1, wx1, wy2, wx2 = window
y1, x1, y2, x2 = boxes
# Clip
y1 = torch.max(torch.min(y1, wy2), wy1)
x1 = torch.max(torch.min(x1, wx2), wx1)
y2 = torch.max(torch.min(y2, wy2), wy1)
x2 = torch.max(torch.min(x2, wx2), wx1)
clipped = torch.stack([x1, y1, x2, y2], dim=2)
return clipped相关资源
项目
- JenifferWuUCLA/pulmonary-nodules-MaskRCNN: Mask R-CNN for Pulmonary Nodules Diagnosis, using TensorFlow 天池医疗 AI 大赛:Mask R-CNN 肺部结节智能检测(Segmentation + Classification)
- facebookresearch/maskrcnn-benchmark: Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch.
- leon-liangwu/MaskYolo_Caffe: YOLO V2 & V3 , YOLO Combined with RCNN and MaskRCNN
- TannerGilbert/MaskRCNN-Object-Detection-and-Segmentation: Train your own custom MaskRCNN Object Detection and Instance Segmentation model.
- CharlesShang/FastMaskRCNN: Mask RCNN in TensorFlow
- buseyaren/installation-guide-of-maskrcnn: Mask R-CNN creates a high-quality segmentation mask in addition to the Faster R-CNN network. In addition to class labels and scores, a segmentation mask is created for the objects detected by this neural network. In this repository, using Anaconda prompt step by step Mask R-CNN setup is shown.
博客
论文
- arxiv.org/pdf/1703.06870
- MULAN: Multitask Universal Lesion Analysis Network for Joint Lesion Detection, Tagging, and Segmentation
- RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free
- FCOS: Fully Convolutional One-Stage Object Detection
- Is Sampling Heuristics Necessary in Training Deep Object Detectors?
